Note
This tutorial was generated from an IPython notebook that can be downloaded here.
A quick intro to PyMC3 for exoplaneteers¶
Hamiltonian Monte Carlo (HMC) methods haven’t been widely used in astrophysics, but they are the standard methods for probabilistic inference using Markov chain Monte Carlo (MCMC) in many other fields. exoplanet is designed to provide the building blocks for fitting many exoplanet datasets using this technology, and this tutorial presents some of the basic features of the PyMC3 modeling language and inference engine. The documentation for PyMC3 includes many other tutorials that you should check out to get more familiar with the features that are available.
In this tutorial, we will go through two simple examples of fitting some data using PyMC3. The first is the classic fitting a line to data with unknown error bars, and the second is a more relevant example where we fit a radial velocity model to the public radial velocity observations of 51 Peg. You can read more about fitting lines to data in the bible of line fitting and you can see another example of fitting the 51 Peg data using HMC (this time using Stan) here.
Hello world (AKA fitting a line to data)¶
My standard intro to a new modeling language or inference framework is to fit a line to data. So. Let’s do that with PyMC3.
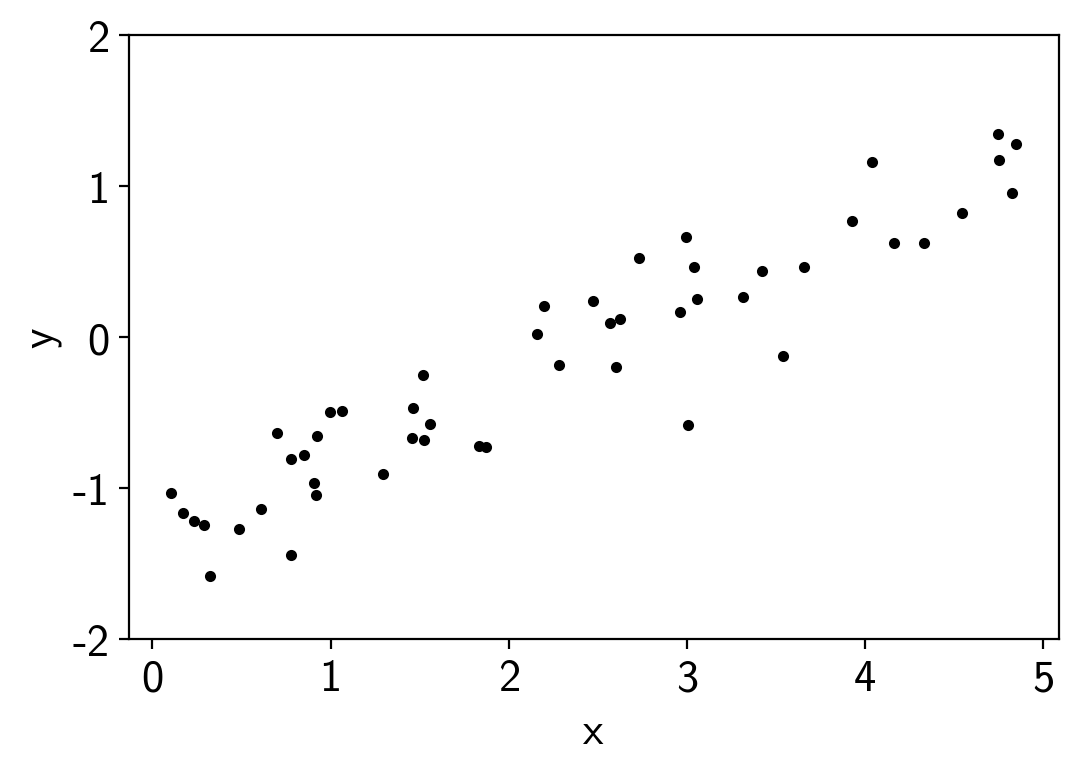
To start, we’ll generate some fake data using a linear model. Feel free to change the random number seed to try out a different dataset.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
true_m = 0.5
true_b = -1.3
true_logs = np.log(0.3)
x = np.sort(np.random.uniform(0, 5, 50))
y = true_b + true_m * x + np.exp(true_logs) * np.random.randn(len(x))
plt.plot(x, y, ".k")
plt.ylim(-2, 2)
plt.xlabel("x")
plt.ylabel("y");
To fit a model to these data, our model will have 3 parameters: the slope \(m\), the intercept \(b\), and the log of the uncertainty \(\log(\sigma)\). To start, let’s choose broad uniform priors on these parameters:
Then, the log-likelihood function will be
[Note: the second normalization term is needed in this model because we are fitting for \(\sigma\) and the second term is not a constant.]
Another way of writing this model that might not be familiar is the following:
This is the way that a model like this is often defined in statistics and it will be useful when we implement out model in PyMC3 so take a moment to make sure that you understand the notation.
Now, let’s implement this model in PyMC3. The documentation for the distributions available in PyMC3’s modeling language can be found here and these will come in handy as you go on to write your own models.
import pymc3 as pm
with pm.Model() as model:
# Define the priors on each parameter:
m = pm.Uniform("m", lower=-5, upper=5)
b = pm.Uniform("b", lower=-5, upper=5)
logs = pm.Uniform("logs", lower=-5, upper=5)
# Define the likelihood. A few comments:
# 1. For mathematical operations like "exp", you can't use
# numpy. Instead, use the mathematical operations defined
# in "pm.math".
# 2. To condition on data, you use the "observed" keyword
# argument to any distribution. In this case, we want to
# use the "Normal" distribution (look up the docs for
# this).
pm.Normal("obs", mu=m*x+b, sd=pm.math.exp(logs), observed=y)
# This is how you will sample the model. Take a look at the
# docs to see that other parameters that are available.
trace = pm.sample(draws=1000, tune=1000, chains=2)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 4 jobs)
NUTS: [logs, b, m]
Sampling 2 chains: 100%|██████████| 4000/4000 [00:02<00:00, 1527.10draws/s]
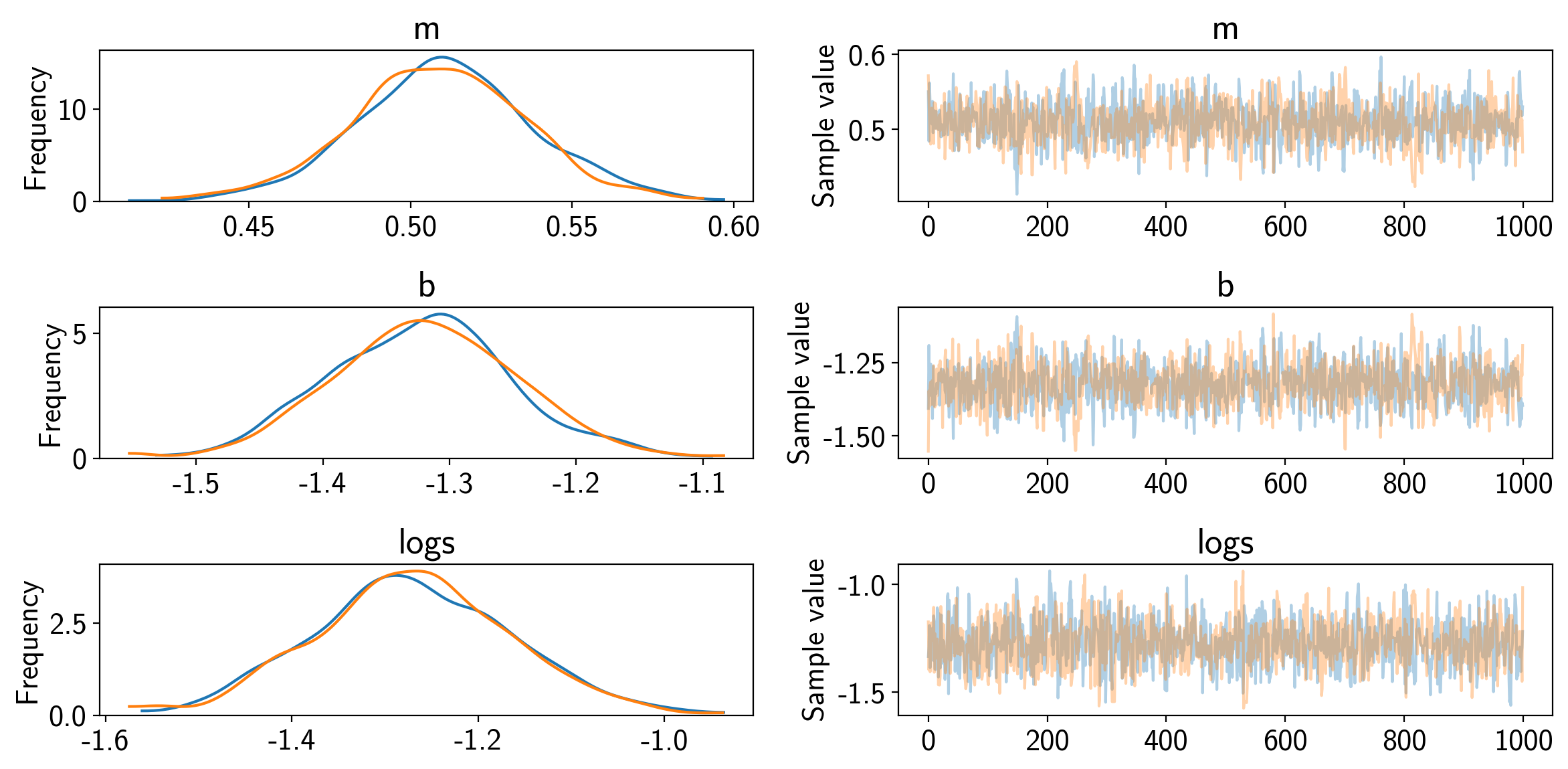
Now since we now have samples, let’s make some diagnostic plots. The first plot to look at is the “traceplot” implemented in PyMC3. In this plot, you’ll see the marginalized distribution for each parameter on the left and the trace plot (parameter value as a function of step number) on the right. In each panel, you should see two lines with different colors. These are the results of different independent chains and if the results are substantially different in the different chains then there is probably something going wrong.
pm.traceplot(trace, varnames=["m", "b", "logs"]);
It’s also good to quantify that “looking substantially different”
argument. This is implemented in PyMC3 as the “summary” function. In
this table, some of the key columns to look at are n_eff and
Rhat. * n_eff shows an estimate of the number of effective (or
independent) samples for that parameter. In this case, n_eff should
probably be around 500 per chain (there should have been 2 chains run).
* Rhat shows the Gelman–Rubin
statistic
and it should be close to 1.
pm.summary(trace, varnames=["m", "b", "logs"])
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| m | 0.509379 | 0.026840 | 0.000868 | 0.453696 | 0.562176 | 928.294846 | 1.001888 |
| b | -1.321782 | 0.071442 | 0.002324 | -1.450008 | -1.169206 | 1024.597914 | 1.000324 |
| logs | -1.271705 | 0.105530 | 0.002755 | -1.474413 | -1.067339 | 1157.270457 | 0.999515 |
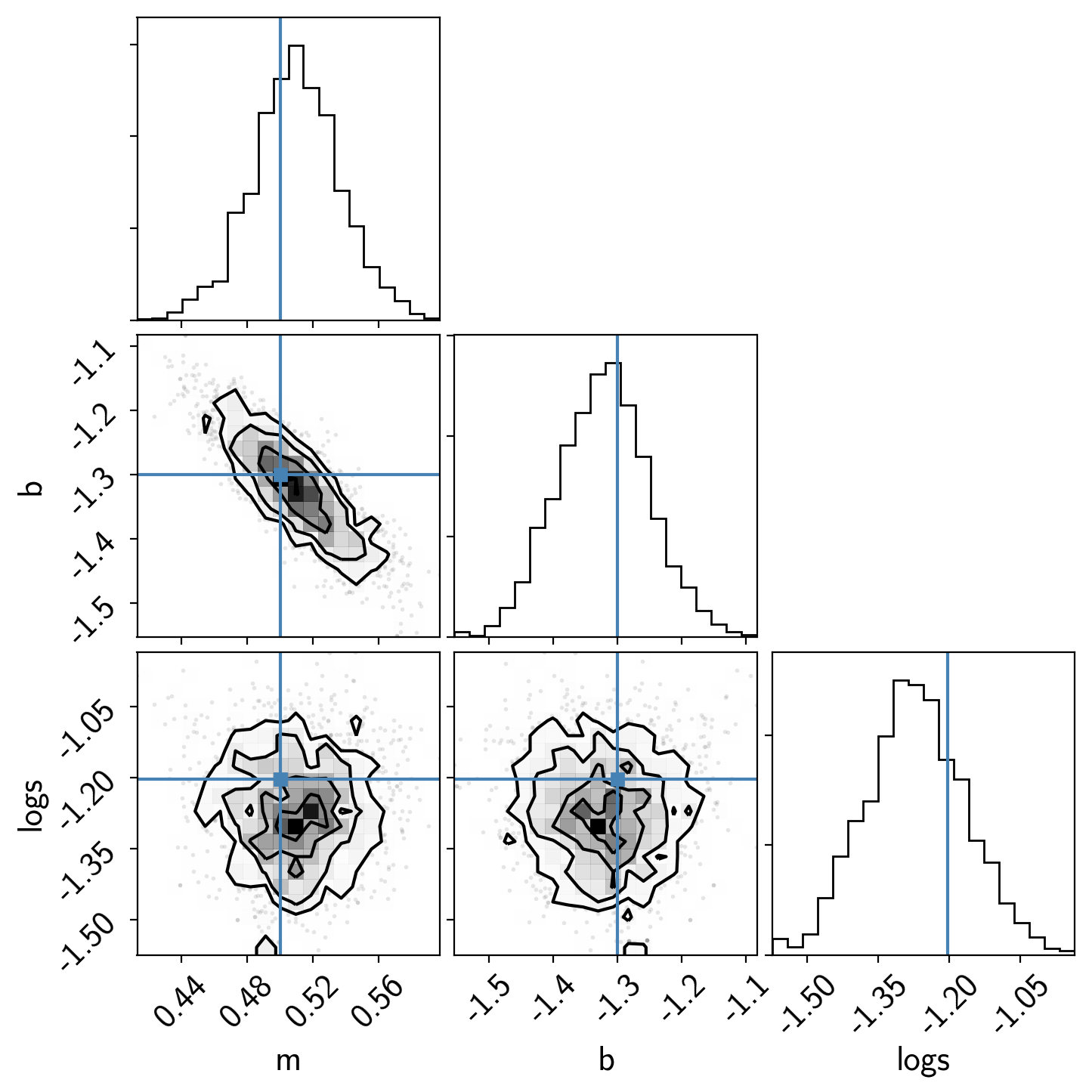
The last diagnostic plot that we’ll make here is the corner plot made
using corner.py. The easiest way to
do this using PyMC3 is to first convert the trace to a Pandas
DataFrame and then pass that to
corner.py.
import corner # https://corner.readthedocs.io
samples = pm.trace_to_dataframe(trace, varnames=["m", "b", "logs"])
corner.corner(samples, truths=[true_m, true_b, true_logs]);
Extra credit: Here are a few suggestions for things to try out while getting more familiar with PyMC3:
- Try initializing the parameters using the
testvalargument to the distributions. Does this improve performance in this case? It will substantially improve performance in more complicated examples. - Try changing the priors on the parameters. For example, try the “uninformative” prior recommended by Jake VanderPlas on his blog.
- What happens as you substantially increase or decrease the simulated noise? Does the performance change significantly? Why?
A more realistic example: radial velocity exoplanets¶
While the above example was cute, it doesn’t really fully exploit the power of PyMC3 and it doesn’t really show some of the real issues that you will face when you use PyMC3 as an astronomer. To get a better sense of how you might use PyMC3 in Real Life™, let’s take a look at a more realistic example: fitting a Keplerian orbit to radial velocity observations.
One of the key aspects of this problem that I want to highlight is the fact that PyMC3 (and the underlying model building framework Theano) don’t have out-of-the-box support for the root-finding that is required to solve Kepler’s equation. As part of the process of computing a Keplerian RV model, we must solve the equation:
for the eccentric anomaly \(E\) given some mean anomaly \(M\) and eccentricity \(e\). There are commonly accepted methods of solving this equation using Newton’s method, but if we want to expose that to PyMC3, we have to define a custom Theano operation with a custom gradient. I won’t go into the details of the math (because I blogged about it) and I won’t go into the details of the implementation (because you can take a look at it on GitHub). So, for this tutorial, we’ll use the custom Kepler solver that is implemented as part of exoplanet and fit the publicly available radial velocity observations of the famous exoplanetary system 51 Peg using PyMC3.
First, we need to download the data from the exoplanet archive:
import requests
import pandas as pd
import matplotlib.pyplot as plt
# Download the dataset from the Exoplanet Archive:
url = "https://exoplanetarchive.ipac.caltech.edu/data/ExoData/0113/0113357/data/UID_0113357_RVC_001.tbl"
r = requests.get(url)
if r.status_code != requests.codes.ok:
r.raise_for_status()
data = np.array([l.split() for l in r.text.splitlines()
if not l.startswith("\\") and not l.startswith("|")],
dtype=float)
t, rv, rv_err = data.T
t -= np.mean(t)
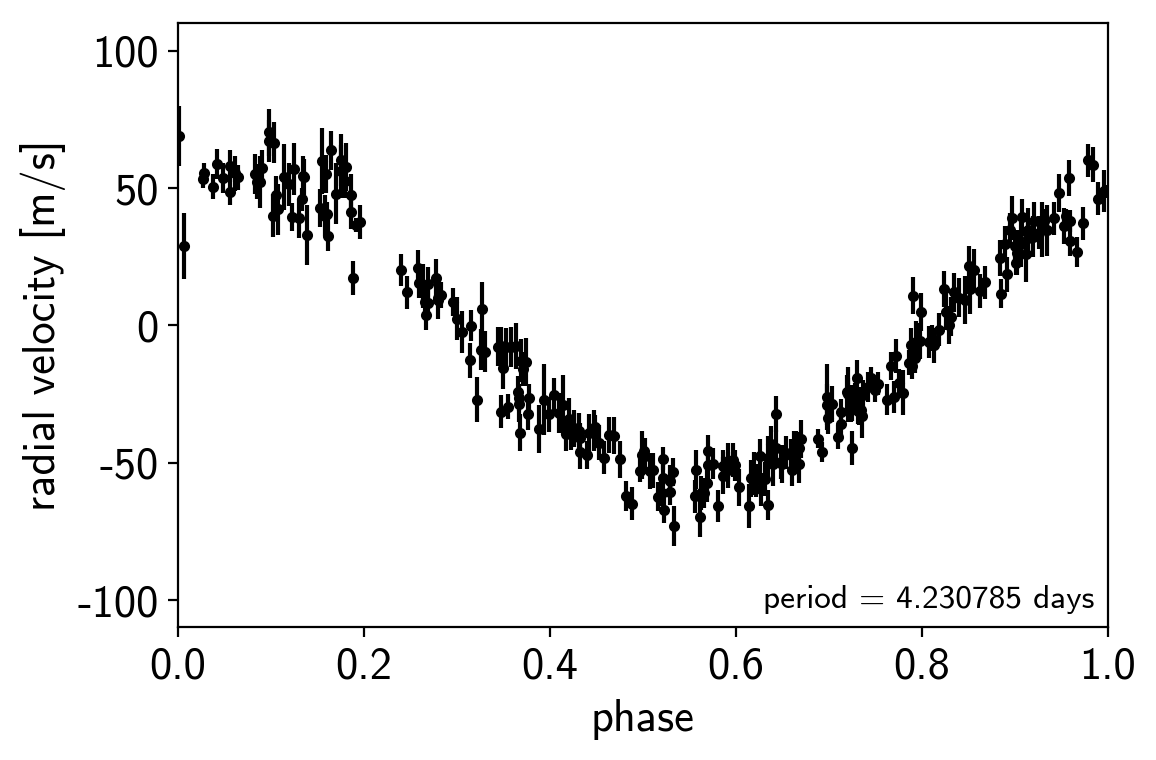
# Plot the observations "folded" on the published period:
# Butler et al. (2006) https://arxiv.org/abs/astro-ph/0607493
lit_period = 4.230785
plt.errorbar((t % lit_period)/lit_period, rv, yerr=rv_err, fmt=".k", capsize=0)
plt.xlim(0, 1)
plt.ylim(-110, 110)
plt.annotate("period = {0:.6f} days".format(lit_period),
xy=(1, 0), xycoords="axes fraction",
xytext=(-5, 5), textcoords="offset points",
ha="right", va="bottom", fontsize=12)
plt.ylabel("radial velocity [m/s]")
plt.xlabel("phase");
Now, here’s the implementation of a radial velocity model in PyMC3. Some of this will look familiar after the Hello World example, but things are a bit more complicated now. Take a minute to take a look through this and see if you can follow it. There’s a lot going on, so I want to point out a few things to pay attention to:
- All of the mathematical operations (for example
expandsqrt) are being performed using Theano instead of NumPy. - All of the parameters have initial guesses provided. This is an example where this makes a big difference because some of the parameters (like period) are very tightly constrained.
- Some of the lines are wrapped in
Deterministicdistributions. This can be useful because it allows us to track values as the chain progresses even if they’re not parameters. For example, after sampling, we will have a sample forbkg(the background RV trend) for each step in the chain. This can be especially useful for making plots of the results. - Similarly, at the end of the model definition, we compute the RV curve for a single orbit on a fine grid. This can be very useful for diagnosing fits gone wrong.
- For parameters that specify angles (like \(\omega\), called
win the model below), it can be inefficient to sample in the angle directly because of the fact that the value wraps around at \(2\pi\). Instead, it can be better to sample the unit vector specified by the angle. In practice, this can be achieved by sampling a 2-vector from an isotropic Gaussian and normalizing the components by the norm. This is implemented as part of exoplanet in theexoplanet.distributions.Angleclass.
import theano.tensor as tt
from exoplanet.orbits import get_true_anomaly
from exoplanet.distributions import Angle
with pm.Model() as model:
# Parameters
logK = pm.Uniform("logK", lower=0, upper=np.log(200),
testval=np.log(0.5*(np.max(rv) - np.min(rv))))
logP = pm.Uniform("logP", lower=0, upper=np.log(10),
testval=np.log(lit_period))
phi = pm.Uniform("phi", lower=0, upper=2*np.pi, testval=0.1)
e = pm.Uniform("e", lower=0, upper=1, testval=0.1)
w = Angle("w")
logjitter = pm.Uniform("logjitter", lower=-10, upper=5,
testval=np.log(np.mean(rv_err)))
rv0 = pm.Normal("rv0", mu=0.0, sd=10.0, testval=0.0)
rvtrend = pm.Normal("rvtrend", mu=0.0, sd=10.0, testval=0.0)
# Deterministic transformations
n = 2*np.pi*tt.exp(-logP)
P = pm.Deterministic("P", tt.exp(logP))
K = pm.Deterministic("K", tt.exp(logK))
cosw = tt.cos(w)
sinw = tt.sin(w)
s2 = tt.exp(2*logjitter)
t0 = (phi + w) / n
# The RV model
bkg = pm.Deterministic("bkg", rv0 + rvtrend * t / 365.25)
M = n * t - (phi + w)
# This is the line that uses the custom Kepler solver
f = get_true_anomaly(M, e + tt.zeros_like(M))
rvmodel = pm.Deterministic(
"rvmodel", bkg + K * (cosw*(tt.cos(f) + e) - sinw*tt.sin(f)))
# Condition on the observations
pm.Normal("obs", mu=rvmodel, sd=rv_err, observed=rv)
# Compute the phased RV signal
phase = np.linspace(0, 1, 500)
M_pred = 2*np.pi * phase - (phi + w)
f_pred = get_true_anomaly(M_pred, e + tt.zeros_like(M_pred))
rvphase = pm.Deterministic(
"rvphase", K * (cosw*(tt.cos(f_pred) + e) - sinw*tt.sin(f_pred)))
In this case, I’ve found that it is useful to first optimize the
parameters to find the “maximum a posteriori” (MAP) parameters and then
start the sampler from there. This is useful here because MCMC is not
designed to find the maximum of the posterior; it’s just meant to
sample the shape of the posterior. The performance of all MCMC methods
can be really bad when the initialization isn’t good (especially when
some parameters are very well constrained). To find the maximum a
posteriori parameters using PyMC3, you can use the find_MAP
function:
with model:
map_params = pm.find_MAP()
logp = -869.97, ||grad|| = 2.5446e+05: 100%|██████████| 128/128 [00:00<00:00, 938.12it/s]
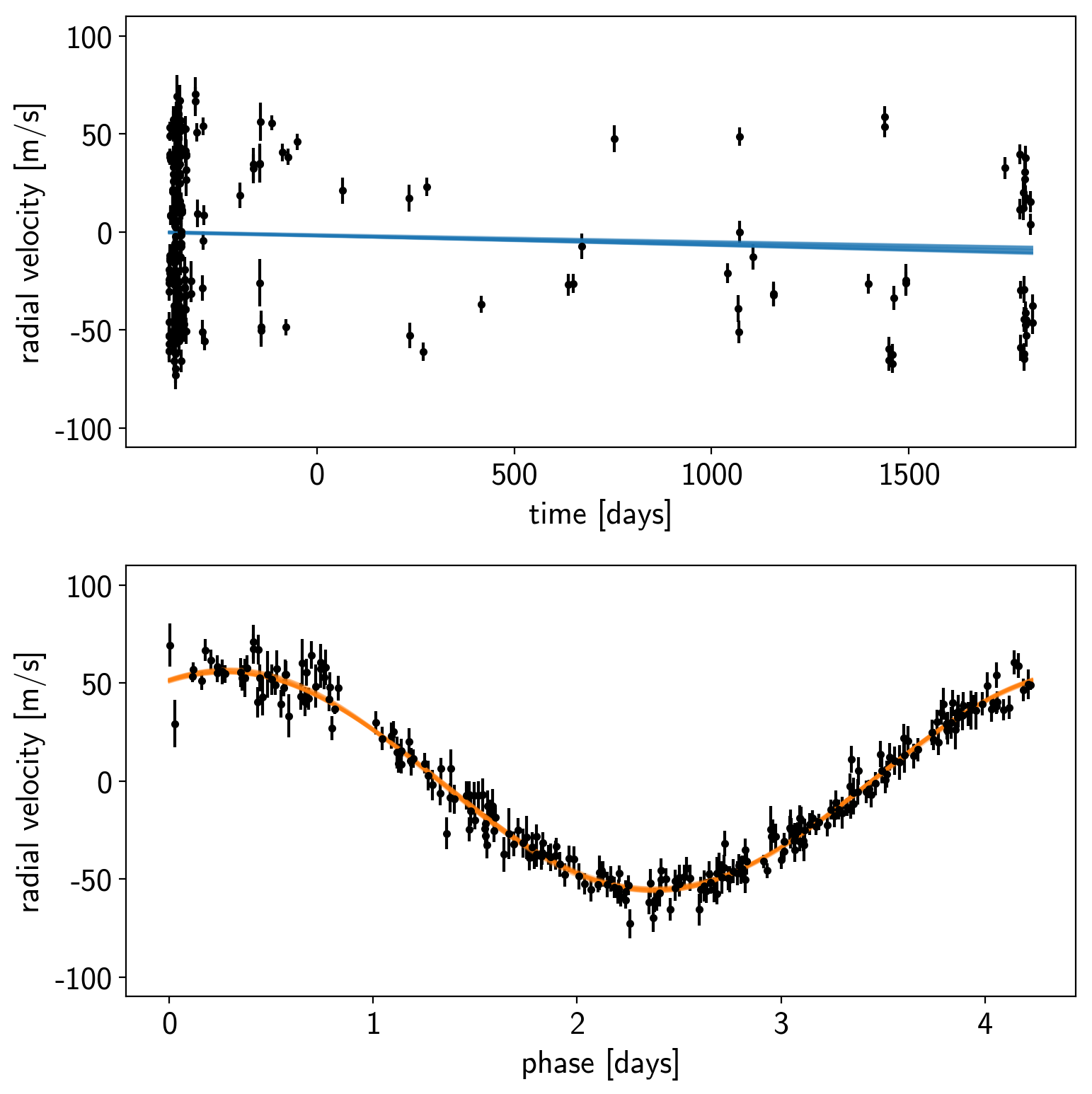
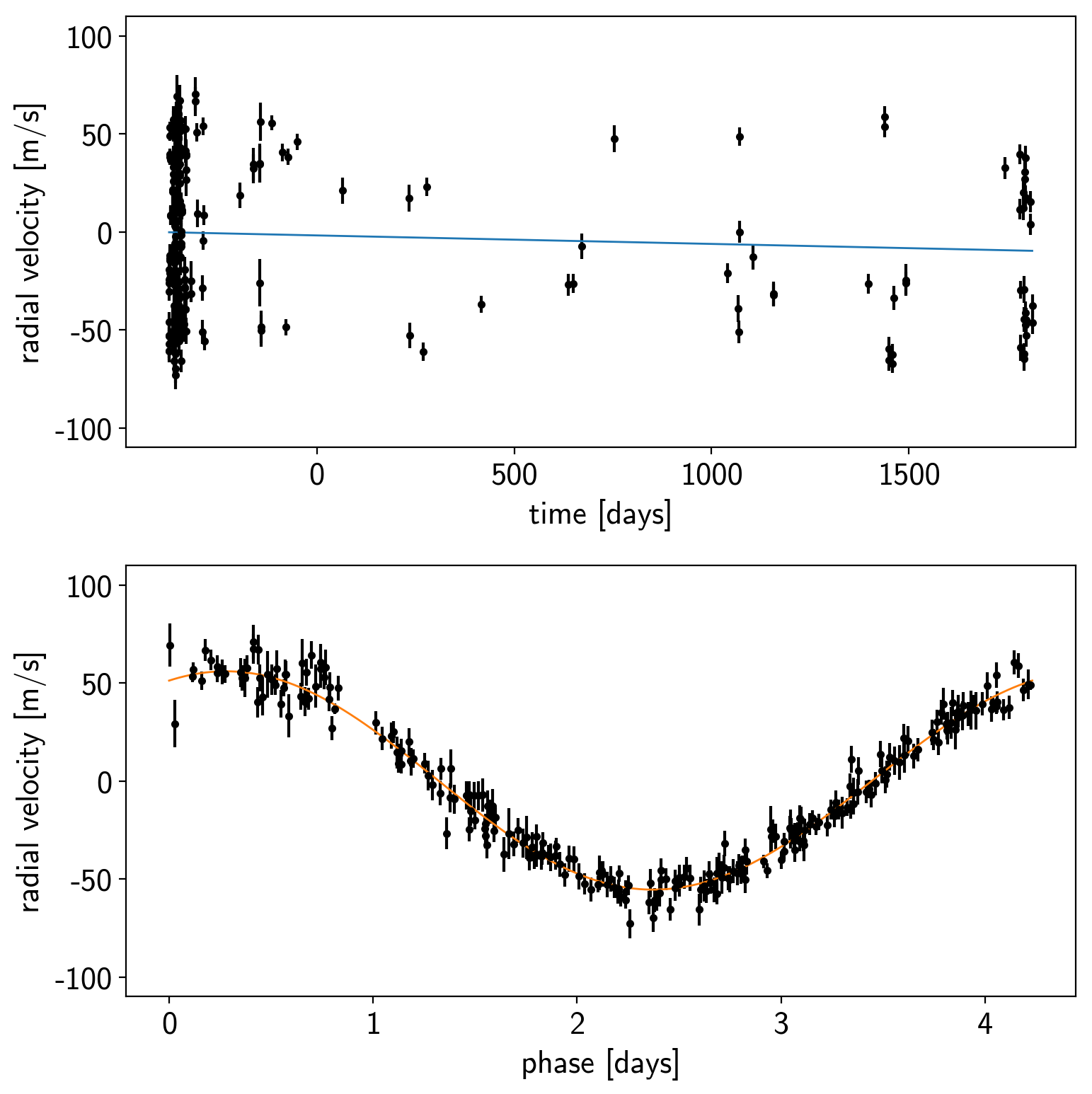
Let’s make a plot to check that this initialization looks reasonable. In the top plot, we’re looking at the RV observations as a function of time with the initial guess for the long-term trend overplotted in blue. In the lower panel, we plot the “folded” curve where we have wrapped the observations onto the best-fit period and the prediction for a single overplotted in orange. If this doesn’t look good, try adjusting the initial guesses for the parameters and see if you can get a better fit.
Exercise: Try changing the initial guesses for the parameters (as
specified by the testval argument) and see how sensitive the results
are to these values. Are there some parameters that are less important?
Why is this?
fig, axes = plt.subplots(2, 1, figsize=(8, 8))
period = map_params["P"]
ax = axes[0]
ax.errorbar(t, rv, yerr=rv_err, fmt=".k")
ax.plot(t, map_params["bkg"], color="C0", lw=1)
ax.set_ylim(-110, 110)
ax.set_ylabel("radial velocity [m/s]")
ax.set_xlabel("time [days]")
ax = axes[1]
ax.errorbar(t % period, rv - map_params["bkg"], yerr=rv_err, fmt=".k")
ax.plot(phase * period, map_params["rvphase"], color="C1", lw=1)
ax.set_ylim(-110, 110)
ax.set_ylabel("radial velocity [m/s]")
ax.set_xlabel("phase [days]")
plt.tight_layout()
Now let’s sample the posterior starting from our MAP estimate.
with model:
trace = pm.sample(draws=2000, tune=1000, start=map_params, chains=2)
Auto-assigning NUTS sampler... Initializing NUTS using jitter+adapt_diag... Multiprocess sampling (2 chains in 4 jobs) NUTS: [rvtrend, rv0, logjitter, w, e, phi, logP, logK] Sampling 2 chains: 100%|██████████| 6000/6000 [00:23<00:00, 250.56draws/s] There was 1 divergence after tuning. Increase target_accept or reparameterize. There was 1 divergence after tuning. Increase target_accept or reparameterize.
As above, it’s always a good idea to take a look at the summary statistics for the chain. If everything went as planned, there should be more than 1000 effective samples per chain and the Rhat values should be close to 1. (Not too bad for less than 30 seconds of run time!)
pm.summary(trace, varnames=["logK", "logP", "phi", "e", "w", "logjitter", "rv0", "rvtrend"])
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| logK | 4.019174 | 0.009202 | 1.643897e-04 | 3.999902 | 4.035857 | 2722.386104 | 0.999831 |
| logP | 1.442387 | 0.000009 | 1.751213e-07 | 1.442370 | 1.442405 | 2791.751863 | 1.000111 |
| phi | 0.397486 | 0.009851 | 1.563376e-04 | 0.378770 | 0.417398 | 3237.303470 | 0.999758 |
| e | 0.010400 | 0.007525 | 1.591293e-04 | 0.000003 | 0.024961 | 2091.180988 | 0.999752 |
| w | 0.675567 | 1.308370 | 2.404887e-02 | -2.180706 | 3.136364 | 2877.775011 | 0.999846 |
| logjitter | -2.580353 | 4.373934 | 8.197521e-02 | -9.945149 | 4.304330 | 3049.842317 | 0.999751 |
| rv0 | -1.824118 | 0.380533 | 7.898370e-03 | -2.535688 | -1.068448 | 2243.485555 | 0.999818 |
| rvtrend | -1.589849 | 0.189784 | 3.185598e-03 | -1.972215 | -1.233311 | 3655.989975 | 1.000145 |
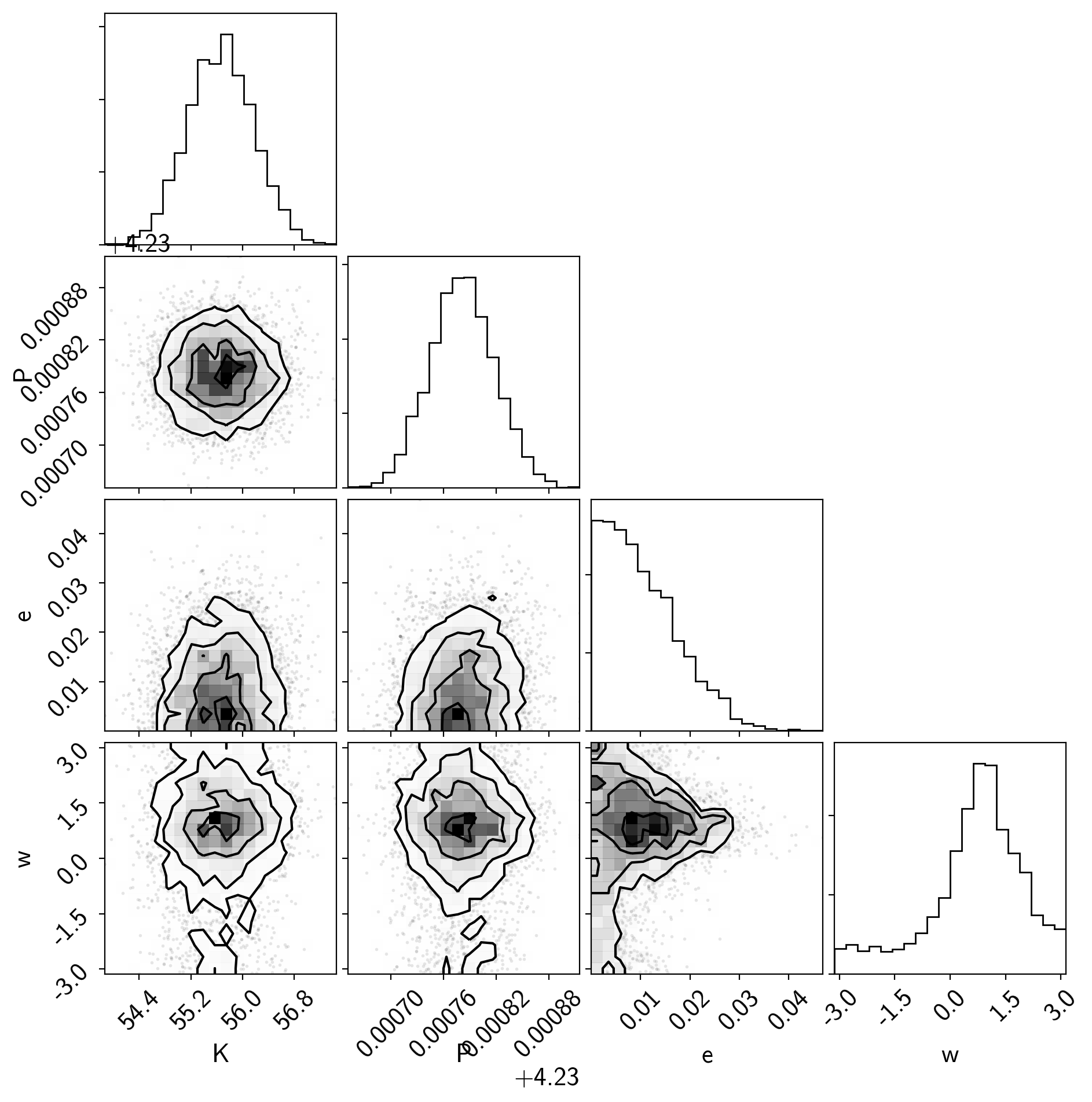
Similarly, we can make the corner plot again for this model.
samples = pm.trace_to_dataframe(trace, varnames=["K", "P", "e", "w"])
corner.corner(samples);
Finally, the last plot that we’ll make here is of the posterior predictive density. In this case, this means that we want to look at the distribution of predicted models that are consistent with the data. As above, the top plot shows the raw observations as black error bars and the RV trend model is overplotted in blue. But, this time, the blue line is actually composed of 25 lines that are samples from the posterior over trends that are consistent with the data. In the bottom panel, the orange lines indicate the same 25 posterior samples for the RV curve of one orbit.
fig, axes = plt.subplots(2, 1, figsize=(8, 8))
period = map_params["P"]
ax = axes[0]
ax.errorbar(t, rv, yerr=rv_err, fmt=".k")
ax.set_ylabel("radial velocity [m/s]")
ax.set_xlabel("time [days]")
ax = axes[1]
ax.errorbar(t % period, rv - map_params["bkg"], yerr=rv_err, fmt=".k")
ax.set_ylabel("radial velocity [m/s]")
ax.set_xlabel("phase [days]")
for i in np.random.randint(len(trace) * trace.nchains, size=25):
axes[0].plot(t, trace["bkg"][i], color="C0", lw=1, alpha=0.3)
axes[1].plot(phase * period, trace["rvphase"][i], color="C1", lw=1, alpha=0.3)
axes[0].set_ylim(-110, 110)
axes[1].set_ylim(-110, 110)
plt.tight_layout()